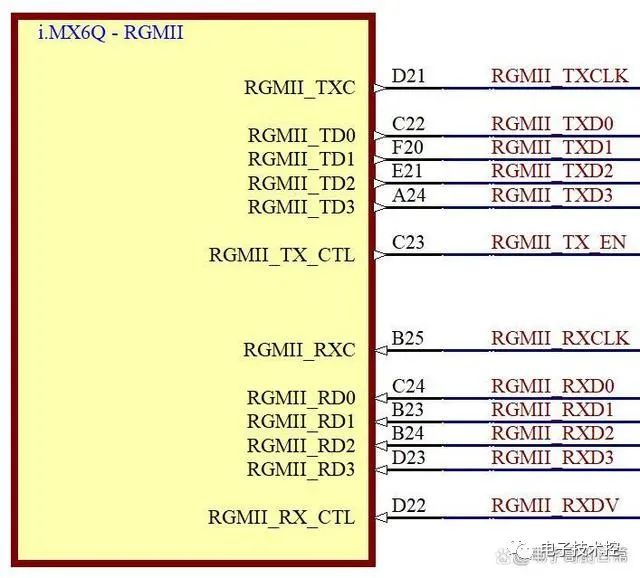
向先进工艺节点的转型,正在重塑移动、汽车、AR/VR 与 AI 边缘设备的高速接口 IP 需求。随着 SoC 设计人员转向顶尖晶圆代工技术,对高度优化的 MIPI PHY 解决方案的需求持续增长。该领域的一项关键进展是:基于台积电 N2P 工艺实现的 C-PHY/D-PHY 组合 IP 正式推出,可为下一代应用提供更高带宽、更低功耗与更优面积效率。MIPI 接口已成为移动与嵌入式系统中连接相机、显示屏和传感器的事实标准。尽管 D-PHY 长期主导生态,但先进图像传感器与超高分辨率显示屏不断提升的数据需求,
关键字:
时钟通道壁垒
台积电
N2P
MIPI C-PHY/D-PHY
组合IP
是德科技(Keysight Technologies)推出 PCIe 7.0 接收器(RX)测试应用 N5991PB7A,进一步扩充其 PCIe 7.0 产品矩阵,实现发射端与接收端端到端完整验证。核心目标实现更快速、自动化的端到端验证,重点解决128 吉比特 / 秒(GT/s)速率下接收器性能验证难题,面向人工智能(AI)与数据中心场景设计。行业观点是德科技网络与数据中心解决方案副总裁约阿希姆・佩林斯博士(Dr. Joachim Peerlings)表示:“128 吉比特 / 秒 PCIe 7.0 接收
关键字:
是德科技
PCIe 7.0
接收器
验证方案
Diodes 公司发布PI6CG33A06,一款面向 PCIe 7.0 系统、具备六路输出的超低抖动时钟发生器,同时兼容前代 PCIe 标准。这款 PCIe 7.0 时钟发生器,主要面向 AI 基础设施所用的服务器、网络设备、高性能计算系统及数据中心平台,于圣克拉拉 PCI-SIG 开发者大会正式发布。面向 AI 基础设施的 PCIe 7.0 时钟发生器PI6CG33A06 可生成 25MHz 与 100MHz 参考时钟,均方根抖动低于 30 飞秒(fs)。优于 PCIe 7.0 规范≤67fs 的最大要
关键字:
Diodes
PCIe 7.0
时钟发生器
PI6CG33A06
近日,在安谋科技Tech Talk AI技术开放麦第二期活动中,NPU高级产品经理Benjamin Ye围绕“周易”X3 NPU IP R2版本升级进行了主题分享,详细介绍了R2版本在算力与算力密度方面的显著提升,并结合“周易”X3智能座舱、AI推理加速芯片及新兴市场等多个领域的落地案例,系统展示了“周易”X3系列NPU的最新进展与广泛应用。 1、最高算力翻倍、算力密度提升超70%据Benjamin Ye介绍,“周易”X3 R2版本相较R1最高算力翻倍,针对W4A8、W4A16主流大模型量化精度
关键字:
安谋科技
周易”X3 NPU IP R2
核心要点设计师常在单一系统中评估5 种以上互连方案,各有明确用途。芯片间(PCIe)与芯粒间(UCIe、BoW)技术目标相近,但实际挑战差异巨大。PCIe、CXL、NVLink、UALink 在大型云计算场景并存;以太网方案持续迭代,依托成熟基础设施具备优势。随着芯片复杂度提升、封装方案增多,系统组件互连的选择空间空前扩大。高效、高速的数据传输至关重要,尤其在 AI 系统中 —— 处理器与内存间的数据量呈指数级增长。数据需以足够快的速度供给处理器,避免延迟,这就要求高带宽、极低延迟。选错互连方案或架构,会
关键字:
互连方案
PCIe
UCIe
人工智能正以远超监管规则的速度渗透整个半导体生态,IP 盗窃、安全漏洞风险急剧上升,且缺乏有效防范手段。从嵌入 EDA 流程的基础模型,到影响设计、验证与物理实现的智能体系统,AI 正在重塑芯片开发方式与风险引入路径。尽管业界普遍认同 AI 治理的必要性,但现有举措碎片化、解读不统一、重意图而轻可衡量结果。简单说:当前治理严重不足,传统监管方式已落后,且难以追上创新步伐。一、AI 治理:缺失的 “护栏”Dana Neustadter(新思科技):“AI 治理需要指导原则、法规、政策与框架流程,引导负责任的
关键字:
无防护
构建 AI
半导体生态
标准分裂
IP 泄露
运行时保障危机
东芝电子元件及存储装置株式会社(“东芝”)今日宣布,推出“TDS5C212MX”和“TDS5B212MX”两款2:1多路复用(Mux)/1:2解复用(De Mux)开关,支持PCIe®6.0[1]、USB4®2.0版[2]等新一代高速接口。新产品即日起开始批量出货。 随着服务器、工业测试设备、机器人及个人电脑不断发展,在日益受限的板载空间内,对PCIe® 6.0与USB4®2.0等超高速、宽带宽差分信号进行可靠切换的需求不断增长。东芝新产品采用自主的SOI工艺(TarfSOI™)[3]
关键字:
东芝
PCIe®6.0
USB4®2.0
高速差分信号器
近日,奎芯科技自主研发的LPDDR5X PHY IP在8nm工艺上顺利完成流片验证。实测不仅稳定达到9600Mbps速率,更超频跑通10.8Gbps,展现出在先进工艺节点上挑战极致带宽的非凡能力,为高性能计算、AI边缘计算等场景提供了高性价比的内存接口方案。满血性能:从标准到巅峰的跨越2-rank DRAM测试子板挂载方案本次流片验证采用了挂载2-rank DRAM测试子板的方案,全面覆盖了从低速到极速的工作场景。满血达标:该IP在1000Mbps至9600Mbps的速率范围内实现了DLL的精准锁定。极致
关键字:
奎芯科技
LPDDR5X
IP
硅验证
9600Mbps
SiFive 完成超额认购的 G 轮融资,募资 4 亿美元,由 Atreides Management 领投,英伟达参投,正式加速进军数据中心 CPU IP 领域。本轮融资后,这家总部位于圣克拉拉的公司估值达36.5 亿美元。据路透社报道,CEO 帕特里克・利特尔表示,本轮融资有望成为其 IPO 前最后一轮私募融资。融资用途与数据中心战略SiFive 表示,新资金将用于三大方向:加速下一代高性能数据中心架构研发扩大工程团队深化其 CPU 平台的软件栈建设具体投入领域包括:高性能标量、向量、矩阵 RISC-
关键字:
SiFive
数据中心
CPU
IP
我供职于一家 RISC‑V IP 公司晶心科技(Andes),但我真心为 Arm 加油 —— 可能比我这个职位的大多数人愿意承认的还要多。不是因为我搞不清谁和谁竞争,而是因为对 Arm 股东最有利的一步,恰恰也是迄今为止给 RISC‑V 带来最大东风的一步。这本质上不是一个 “Arm 对决 RISC‑V” 的故事,而是一个平台经济学的故事:当中立的平台提供商开始与它赋能的客户正面竞争时,会发生什么。一、向价值链上游攀登 —— 这在商业上完全合理纵观历史,Arm 一直在稳步向价值链上游走:从 CPU IP,
关键字:
晶心科技
IP
RISC‑V
Arm
在AI大模型、超算集群和云原生数据中心蓬勃发展的今天,芯片内部和节点中的“数据高速公路”和“存储中枢”正成为制约处理器算力释放和节点整体性能的核心瓶颈。SmartDV作为领先的半导体知识产权(设计IP)与验证IP(VIP)解决方案提供商,正以其全面的高速接口、内存控制器与互连IP产品,为各类AI处理器、加速器和系统级芯片(SoC),高性能计算(HPC) 及数据中心处理器注入“超高速、低延迟、可扩展”的设计基因。3月10日至12日,SmartDV在于德国纽伦堡展览中心举办的2026年嵌入式世界展(Embed
关键字:
SmartDV
连接与存储
IP
算力芯片
1 VPU向高效、高质、低延迟发展随着AI技术的爆发,带来了视频分辨率和数据量的不断攀升,专用于视频编解码处理的VPU应运而生,成为各类视频应用的“超级工匠”。如今,VPU已成为支撑云、边、端等关键场景的核心算力单元,是半导体和AI算力赛道的重要组成部分。VPU主要由两大类芯片/硬件模块构成:一类是VPU芯片;另一种是嵌入在各种SoC、处理器、控制器等芯片/硬件模块中的VPU引擎。但是万变不离其宗,都离不开强大的VPU IP核芯。目前VPU、VPU IP的发展趋势是什么?答案是:在云、边、端场景中AI无
关键字:
VPU
VPU IP
安谋科技Arm China
安谋
2026 年 3 月 16 日,美光科技在英伟达 GTC 2026 大会上正式发布重磅消息:旗下HBM4 高带宽内存、SOCAMM2 内存模块以及业内首款 PCIe 第六代数据中心固态硬盘,均已实现大规模量产并开启批量出货,全系列产品均为英伟达 Vera Rubin AI 平台量身打造,将为智能体 AI、高性能计算等负载提供核心存储算力支撑。核心产品量产信息HBM4 高带宽内存首批量产的为 36GB 12 层堆叠版本,已于 2026 年第一季度出货,引脚速率超 11Gb/s,可提供超 2.8TB/s 的内
关键字:
美光
HBM4
SOCAMM2
内存模块
PCIe
第六代固态硬盘
人工智能的发展之路并非一帆风顺。媒体与华尔街对人工智能行业情绪的任何细微变化,都会表现出极端且剧烈的反应。狄更斯早已预见这般光景:“那是最美好的时代,那是最糟糕的时代;那是智慧的年头,那是愚昧的年头;那是信仰的时期,那是怀疑的时期;那是光明的季节,那是黑暗的季节;那是希望的春天,那是失望的冬天。” 在这些喧嚣的头条背后,人工智能推理的规模化发展正面临一个关键难题:芯片的理论峰值性能与系统厂商能实际保障的性能之间,差距正不断扩大。这一差距对算力的功耗需求和系统安全性,都产生了重大影响。这一性能差距究竟从何而
关键字:
人工智能
IP
Arteris
Ceva-Waves UWB 是业界率先符合 IEEE 802.15.4ab 标准的 UWB IP 协议,可提供高达 30 倍的扩展测距和 4 倍的数据传输速率,适用于安全访问、定位、雷达和先进数据应用. 超宽带 (UWB) 技术正从基于近距离的数字密钥和跟踪器扩展到更远距离的定位、雷达传感和高性能数据应用。为了应对这一转变,领先的智能边缘芯片和软件 IP 授权商 Ceva 公司(纳斯达克股票代码:CEVA)宣布推出其新一代 Ceva-Waves™ UWB IP,这是业界率先符合 IEEE 80
关键字:
Ceva
UWB
IP
传输距离
吞吐量
芯原股份(芯原,股票代码:688521.SH)今日宣布图像处理SoC芯片公司合肥六角形半导体有限公司(简称“六角形半导体”)在其高性能HX77系列图像处理SoC中采用了芯原成熟的IP组合,包括GCNanoUltraV 2.5D图形处理器(GPU)IP、DW100畸变矫正处理器(DeWarp Processing)IP,以及DC9200Nano显示处理器(Display Processing)IP。该SoC芯片已顺利完成流片,并实现一次流片成功。 天相芯HX77系列是一款高度集成、低功耗的图像处理
关键字:
六角形半导体
天相芯
HX77
芯原
Nano IP
AR显示处理器
基于 Ceva 第三代 PentaG 平台的PentaG-NTN加速了卫星网络和蜂窝网络的融合 随着卫星连接迅速成为5G网络最具战略意义和颠覆性的扩展,领先的智能边缘芯片和软件IP授权商Ceva公司(纳斯达克股票代码:CEVA)今日宣布推出PentaG-NTN™,这款新型5G-NTN(非地面网络)调制解调器IP子系统专为支持低地球轨道(LEO)和中地球轨道(MEO)星座的卫星用户终端而设计。PentaG-NTN旨在加速基于标准的卫星连接的部署,使卫星运营商、卫星星座开发商和终端创新者能够更快地将
关键字:
Ceva
PentaG-NTN
5G
高级调制解调器
IP
向多芯粒(Chiplet)集成转型既充满前景,也带来了复杂性。可扩展的互连技术与自动化工具,正成为支撑未来设计的关键要素。芯粒已成为下一代系统架构讨论中的核心主题。当前行业描绘的愿景是:设计团队能够选用不同来源的裸芯,通过标准化接口与简化流程,搭建多芯粒系统。业界常将其类比为现成 IP 组件,期望芯粒能像无源器件甚至单片机一样,易于使用且具备互操作性。然而,这一愿景虽极具吸引力,却与现实仍有很大差距。芯粒集成的现状芯粒通常分为两类架构:同构横向扩展与异构解耦。同构设计在一个封装内使用多个相同裸芯以提升性能
关键字:
芯粒
互操作性
Arteris
IP
Chiplet
NoC
物联网和智能家居市场的爆炸式增长推动了对高度集成、高能效连接解决方案的需求,这些解决方案能够简化设计并加快产品上市速度。为了满足这一需求,领先的智能边缘芯片和软件IP授权商Ceva公司近日布,瑞萨电子株式会社 (Renesas Electronics Corporation) 已将Ceva-Waves Wi-Fi 6和低功耗蓝牙IP集成到其新推出的RA6W1和RA6W2组合式微控制器(MCU)中,为智能家居、工业和消费电子设备提供强大的无线性能。瑞萨电子的 RA6W1 双频 Wi-Fi 6 MCU 和 R
关键字:
Ceva
Wi-Fi 6 IP
蓝牙IP
瑞萨
组合式MCU
Diodes 公司(Diodes)近日宣布推出符合汽车规范的 PI2MEQX2505Q,这是一款 1.8V、2.5Gps MIPI D-PHY ReDriver 信号调节器,具有四条差分数据通道和一条时钟通道,专为 MIPI D-PHY 1.2 协议设计。该器件能在涉及PCB走线、连接器和线缆的通道中再生D-PHY信号,通过补偿频率损耗,提供从CSI-2/DSI來源端到接受端的最佳电气性能。与市面上其他重定时器解决方案不同,PI2MEQX2505Q 配置支持最高2.5Gbps的数据速率,能够满足汽车摄像监
关键字:
Diodes
D-PHY
信号调节器
芯原股份(芯原)近日宣布其ISP8200-FS系列图像信号处理器(ISP)IP的最新增强版本,包括ISP8200-ES和ISP8200L-ES,已实现性能和能效方面的全面提升,可更好地支持复杂的车载摄像头系统。这些增强版IP已成功获得国际检验认证机构TÜV NORD颁发的ISO 26262 ASIL B功能安全认证,充分验证了其在高级驾驶辅助系统(ADAS)及自动驾驶应用中的适用性与可靠性。ISP8200-FS系列IP的最新增强版本最高运行频率可达1.2GHz,并支持多达16路图像传感器数据处理。该系列I
关键字:
芯原
图像信号处理器IP
ISP IP
一、产品概述与性能跃迁Imagination Technologies(以下简称"Imagination")推出了其最新GPU IP产品——Imagination DXTP,专为智能手机和其他功耗受限、但仍致力于为用户提供卓越游戏体验和最新生成式人工智能体验的设备打造。基于先进图形和计算加速技术,DXTP在性能和能效方面实现了重大突破,成为智能手机、平板电脑、笔记本电脑以及非安全关键型汽车应用等场景的理想选择。通过一系列微架构改进,与前代产品IMG DXT GPU相
关键字:
Imagination
DXTP GPU IP
树莓派 AI HAT+ 2 是树莓派 5 的一款新 PCIe 扩展,集成了 Hailo-10H 加速器和 8 GB 板载LPDDR4X。在插件本身添加内存的意义很简单:让更多模型的工作集靠近加速器,而不是依赖Pi的系统内存通过PCIe链路。树莓派AI HAT+ 2新动态此前基于树莓派品牌的 Pi 5 Hailo 插件主要被定位为以摄像头为先的流水线的视觉加速器,如物体检测、分割和姿态估计。AI HAT+ 2 依然符合“螺栓连接 NPU”模式,但板载 8GB 内存使工作负载结构转向即使有计算能力仍占用内存的
关键字:
人工智能
Edge AI
生成式人工智能
PCIe
树莓派
一、产品概述中国上海芯原发布其ISP9000系列图像信号处理器(ISP)IP——面向日益增长的智能视觉应用需求而打造的新一代AI ISP解决方案。ISP9000采用灵活的AI优化架构,提供卓越的图像质量,具备低延迟的多传感器管理能力,并与AI深度融合,是智能机器、监控摄像头和AI PC等应用的理想之选。二、产品优势凭借AI加持的ISP功能,芯原的ISP9000系列IP能够实现卓越的图像质量。其集成了先进的AI降噪(AI NR)算法,结合多尺度2D和3D噪声抑制及YUV域色度噪声抑制(CNR),形成了多域降
关键字:
芯原微电子
ISP9000系列
图像信号处理器
(ISP)IP
总部位于纽约马耳他的GlobalFoundries已签署最终协议,收购Synopsys的处理器IP解决方案业务并将其并入其于2025年收购的RISC-V知识产权供应商MIPS。两家公司表示,目标是构建一个更广泛的“物理人工智能”平台,结合处理器IP、软件工具和晶圆技术,而不是让ARC成为独立的Synopsys业务。ARC处理器IP协议内容根据GlobalFoundries的公告,转移资产包括ARC-V(RISC-V)、ARC“Classic”CPU IP、VPX DSP和NPU系列,以及相关的软件和ASI
关键字:
GlobalFoundries
Synopsys
ARC
IP
2026 年 1 月 7 日,爱达荷州博伊西市 —— 美光科技股份有限公司(纳斯达克股票代码:MU)今日宣布推出美光 3610 NVMe™ SSD,这是业界首款面向客户端计算的 PCIe® 5.0 QLC SSD。这一突破性产品重新定义了主流 PC 和超薄笔记本电脑的性能、效率和容量。3610 SSD 基于久经市场考验的美光 G9 NAND 打造,顺序读取速率高达 11,000 MB/s,顺序写入
关键字:
美光
PCIe 5.0 QLC SSD
QLC SSD
美光刚刚发布了3610 SSD,该SSD支持PCIe 5.0速度,采用了更高密度的四层单元(QLC)芯片。根据公司新闻稿,该芯片采用了G9 NAND,使其能够在同等占用空间内实现竞争性的PCIe 5.0性能。因此,美光表示这是全球首款以紧凑单面M.2 2230形态提供4TB内存的固态硬盘,使制造商能够在轻薄笔记本和掌上设备中集成更多内存。除了更高的存储密度外,它还被宣传为每瓦性能提升43%,以提升电力效率和电池续航。美光移动与客户业务部高级副总裁Mark Montierth表示:“3610 SSD结合了最
关键字:
美光
3610 SSD
PCIe 5.0
QLC SSD
美光宣布了一款面向客户端计算的PCIe Gen5 G9 QLC SSD。基于美光G9 NAND构建的3610 NVMe SSD实现了最高11,000 MB/s的连续读取速度和9,300 MB/s的连续写入速度。它提供4TB单面M.2 2230机型,适合超薄笔记本和具备AI功能的设备。它提供150万IOPS随机读取和160万IOPS随机写入。它采用无 DRAM 架构,采用主机内存缓冲区(HMB)和 DEVSLP 低功耗状态,声称与第四代 TLC 相比,每瓦性能提升了 43%。它在三秒内加载200亿参数的AI
关键字:
CES 2026
美光
客户端计算
PCIe Gen5
G9 QLC
SSD
美普思(MIPS)于国际消费电子展(CES 2026)上发布一款基于RISC-V的人工智能神经处理器知识产权(IP),该产品旨在为边缘端的变换器(Transformer)模型与智能体语言人工智能模型提供算力支持。美普思精简指令集架构 - V 人工智能神经处理器这款处理器被命名为美普思 S8200。据该公司介绍,“它将紧密耦合的人工智能引擎与精简指令集架构 - V 应用核心相整合,可同时加速向量与矩阵运算负载;支持 PyTorch 和 Tensor 两大主流框架;借助一致性集群平铺技术,算力可实现从几十万亿
关键字:
CES 2026
MIPS
RISC-V
人工智能神经处理器
IP
PCI-SIG外围组件互连 Express Gen5(PCIe Gen5)是一种系统协议,主要用于系统中高速的数据传输。PCIe Gen5可实现32 Gb/s的传输速率。PCIe 几乎集成在所有计算机系统中,包括服务器。PCIe是一种复杂的协议,包括链路训练、TLP生成和事务、不同的有效载荷传输、错误TLP、流量控制以及RC和EP模式下的恢复状态验证。在对整个系统进行验证之前,验证协议至关重要。验证工程师通过通用验证方法(UVM)测试平台参与验证PCIe协议。除了验证设置外,仿真工程师还提供验证PCIe协
关键字:
Palladium 模拟器
PCIe
配置
FPGA
pcie 4.0 phy ip介绍
您好,目前还没有人创建词条pcie 4.0 phy ip!
欢迎您创建该词条,阐述对pcie 4.0 phy ip的理解,并与今后在此搜索pcie 4.0 phy ip的朋友们分享。
创建词条
关于我们 -
广告服务 -
企业会员服务 -
网站地图 -
联系我们 -
征稿 -
友情链接 -
手机EEPW
Copyright ©2000-2015 ELECTRONIC ENGINEERING & PRODUCT WORLD. All rights reserved.
《电子产品世界》杂志社 版权所有 北京东晓国际技术信息咨询有限公司
京ICP备12027778号-2 北京市公安局备案:1101082052 京公网安备11010802012473